Table of Contents
Differences : (GANS vs VAEs, GANS vs Diffusion)
- GANS : capture less diversity, and difficult to train.
- Likelihood-Based Model (VAEs, Diffusion Models), short of visual sample quality (before guided-diffusion).
1. Physics Model
Transform noise into data through an iterative diffusion process. Each iteration using model to predict noise, assuming gaussian distribution, using fixed variance.

Classifier Guidance (sample each iteration on label y, with classifier) :
\[p_{\theta, \phi}(x_{t}|x_{t+1},y) = Z p_{\theta}(x_{t}|x_{t+1})p_{\phi}(y|x_{t})\]![]() Diffusion Models: A Comprehensive Survey of Methods and Applications 2024 Github with all the paper links
Diffusion Models: A Comprehensive Survey of Methods and Applications 2024 Github with all the paper links
OpenAI Guided Diffusion guided-diffusion: ![]() DALL·E 2.
DALL·E 2.
- The Physics Principle That Inspired Modern AI Art heavily inspired by nonequilibrium thermodynamics ~ the probability distribution.
 Denoising Diffusion Probabilistic Models 2020, github.
Denoising Diffusion Probabilistic Models 2020, github.- Diffusion Models Beat GANs on Image Synthesis 2021. with
Classifier Guidance .
Image-Text, diffusion combined with a language transformer:
 Blended Diffusion for Text-driven Editing of Natural Images 2022, github, DDPM + CLIP (
Blended Diffusion for Text-driven Editing of Natural Images 2022, github, DDPM + CLIP (guided fusion using CLIP loss gradient - instead of a classifier ), and combine the noised raw image to preserve the background. but very slow.- Blended Latent Diffusion 2023, github. DDPM + CLIP + VAE, process diffusion in the latent space (
VAE encoded space ). - DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation 2023. Finetune the model to bind a unique identifier(token) with that specific subject. Text prompt -> SentencePiece tokenizer -> T5-XXL language model.
More Physics Models, The Physical Process That Powers a New Type of Generative AI.
- Yukawa potential: allows you to annihilate particles or split a particle into two.
- GenPhys: From Physical Processes to Generative Models 2023 the Yukawa potential, which relates to the weak nuclear force.
- Electrostatic Forces:
- PFGM++: Unlocking the Potential of Physics-Inspired Generative Models 2023. includes a new parameter, D - the dimensionality of the system. the electric field’s laws are different for different dimensions.
- Low D, the model is more robust - more tolerant of the errors made in estimating the electric field.
- High D, the neural network becomes easier to train, requiring less data to master its artistic skills. (when there are more dimensions, the model has fewer electric fields to keep track of.)
- Poisson Flow Generative Models 2022. data is represented by charged particles, which combine to create an electric field whose properties depend on the distribution of the charges at any given moment.
2. VAE (variational auto-encoder)
Encoder-Decoder Transformer.
![]() DALL-E : Zero-Shot Text-to-Image Generation 2021, image token (32x32x8192 : dVAE - discrete variational autoencoder, based on GPT-3) + text token (256 : BPE-encode) -> train an autoregressive transformer (models the
DALL-E : Zero-Shot Text-to-Image Generation 2021, image token (32x32x8192 : dVAE - discrete variational autoencoder, based on GPT-3) + text token (256 : BPE-encode) -> train an autoregressive transformer (models the
3. GAN
![]() Generative Adversarial Networks 2014
Generative Adversarial Networks 2014

CLIP : Contrastive Language-Image Pre-training:
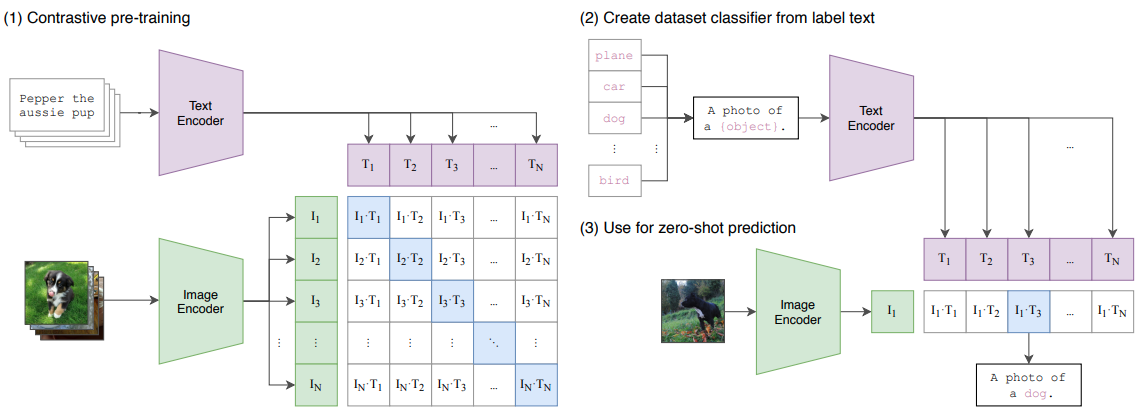
![]() CLIP : Learning Transferable Visual Models From Natural Language Supervision 2021. Image-Text pairing: predict the most relevant text snippet, given an image.
CLIP : Learning Transferable Visual Models From Natural Language Supervision 2021. Image-Text pairing: predict the most relevant text snippet, given an image.
- Learning from natural language:
- Large Dataset Transfer. NLP tasks can use web-scale collections of text. while CV tasks depend on crowd-labeled datasets.
Use web text in CV leads to breakthough (since transfer trained on large dataset always perform better) . - Create connects that representation to language which enables flexible zero-shot transfer.
- Large Dataset Transfer. NLP tasks can use web-scale collections of text. while CV tasks depend on crowd-labeled datasets.
- Dataset : over 400 million pairs. (
how to make such dataset? ) - Model : a image encoder (ViT) & a text encoder (Transformer).
Predicts the correct pairings of image and text (instead of words).
CLIP + GAN :
- StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery 2021 : StyleGAN + CLIP. works for the whole image.
- add CLIP loss, facial identification loss.
- Global direction (make train faster) : direction in CLIP space -> direction in style space.
- Paint by Word 2021 (paintbrush) introduces a mask to control text-image editing.
- network 1 : scores [masked image]-[text] consistency.
- network 2 : enforces on realism.
- GANs create abstract artworks.
Cannot edit image - while perserve not-masked area of the orginal image.