Table of Contents
1. Mapping & Localization
1.1 Pipeline Design
Blog: Methods for visual localization.
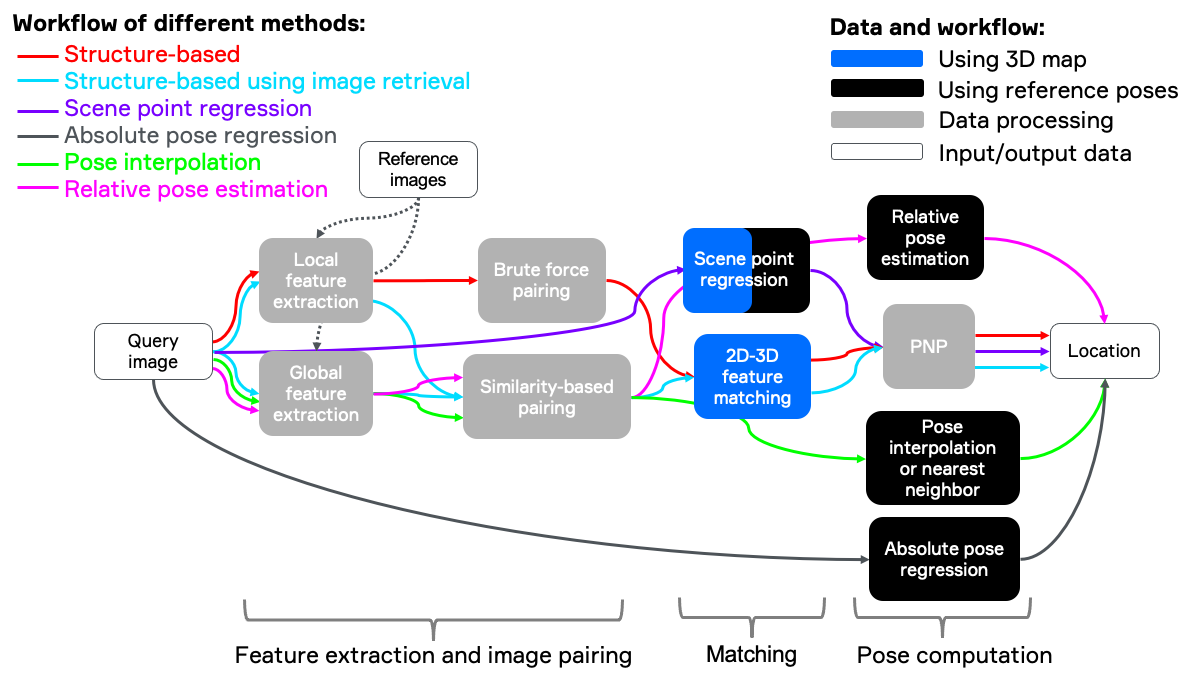
- HLOC (blue line) : point based mapping (feature extraction + match + sfm), image retrieval, PnP. The most sophisticated method, but too many algorithm modules, make the system complicated. And the development cost is large, since we need to refine each module separatly, then fused to test, all the modules are entangled to each other.
- Retrieval Based (green line) : all based on image retrieval, which is a weak pose, cannot reach high accuracy.
- End-to-end regression (black line) : I don’t buy the idea. we cannot afford train a model for each scene.
- Relatve pose (purple line) : Single module, pose strong. But relative pose constraints might suffer degenerated scenes.
1.2 Local Feature
- SIFT + RANSAC
- SuperPoint + SuperGlue
- detector-free: LOFTR
1.3 Global Descriptor
Has two type of understanding:
| Visual geo-localization (VG) | Image Retrieval | |
|---|---|---|
| description | Image localization task, find image close in pose (6dof) space. | Find images with similar look (not necessarily close in pose space) |
| loss | pose space distance | image similarity, hard to define |
| method | rich of Deep Learning methods | found only classic method |
| implementation | cosplace, NetVLAD | Bag-of-Words, VLAD, AnyLoc |
We should make a model to do real 'Image Retrieval' task.
- choose Classification model, which is more efficient to train.
- transform matched images to id.
1.4 Mapping
Point based mapping:
- Bundle adjustment based mapping: Hierarchical-Localization.
- Global Averaging based mapping: GTSFM.
- Optimization Distribution : DABA, ADMM BA.
Line based mapping: see page.
1.5 Post Processing
- Map Simplification : ILP Summarization, GNN Summarization.
2. Product Analysis
![]() Lightship AR : Product Session: Introducing Lightship 3.0:
Lightship AR : Product Session: Introducing Lightship 3.0:
- Unity Development:
- Compatible with ArFoundation feature.
- Playback : Streamlined Development. run with recording.
- Contextual Awareness (depth, occlusion, mesh, semantic).
- Map & Location :
- Lightship Maps (3d plannar low-ploy map).
- Visual Positioning System : (user uploaded) landmark based localization.
- Shared AR : multiplayers.
2023
![]() RelPose++: Recovering 6D Poses from Sparse-view Observations.
RelPose++: Recovering 6D Poses from Sparse-view Observations.
![]() AnyLoc: Towards Universal Visual Place Recognition. use DINOv2 vision transformer (Layer 31) (or CLIP) to extract per pixel features. then apply VLAD aggregation. Express State-of-Art accuracy.
AnyLoc: Towards Universal Visual Place Recognition. use DINOv2 vision transformer (Layer 31) (or CLIP) to extract per pixel features. then apply VLAD aggregation. Express State-of-Art accuracy.
![]() Two-view Geometry Scoring Without Correspondences, github. A fundamental matrix scoring network. Outperform MAGSAC++ in selecting best candidate. (and analysis RANSAC failures)
Two-view Geometry Scoring Without Correspondences, github. A fundamental matrix scoring network. Outperform MAGSAC++ in selecting best candidate. (and analysis RANSAC failures)
![]() DABA: Decentralized and Accelerated Large-Scale Bundle Adjustment. Dencentralized and without centrial device (while ADMM BA needs a centrial device and sensitive to prarmeter tuning). detail notes.
DABA: Decentralized and Accelerated Large-Scale Bundle Adjustment. Dencentralized and without centrial device (while ADMM BA needs a centrial device and sensitive to prarmeter tuning). detail notes.
- Using Majorization Minimizaion: deriving a novel surrogate function (an upper bound of the original loss function) that decouples optimization variables from different devices.
- Reformulate the reprojection error to surrogate function.
- Nesterov’s Acceleration (from Distributed Photometric Bundle Adjustment) using momentum update.
- Adaptive Restart to ensure convergence (problem caused by nonconvexity of BA).
![]() IMAGEBIND: One Embedding Space To Bind Them All bind many input (image, text, depth, audio, imu, thermal) together.
Can Using audio and images to retrieve related images -> Image Retrieval. (& other capabilities).
IMAGEBIND: One Embedding Space To Bind Them All bind many input (image, text, depth, audio, imu, thermal) together.
Can Using audio and images to retrieve related images -> Image Retrieval. (& other capabilities).
![]() MixVPR: Feature Mixing for Visual Place Recognition take advantage of the capacity of fully connected layers to automatically aggregate features in a holistic way.
MixVPR: Feature Mixing for Visual Place Recognition take advantage of the capacity of fully connected layers to automatically aggregate features in a holistic way.
![]() Are Local Features All You Need for Cross-Domain Visual Place Recognition? evaluate rerank methods (re-rank a set of candidates (usually through spatial verification) provided through image retrieval methods).
Are Local Features All You Need for Cross-Domain Visual Place Recognition? evaluate rerank methods (re-rank a set of candidates (usually through spatial verification) provided through image retrieval methods).
![]() Refinement for Absolute Pose Regression with Neural Feature Synthesis
Refinement for Absolute Pose Regression with Neural Feature Synthesis
2022
![]() TransVPR: Transformer-based place recognition with multi-level attention aggregation
use self-attention operation in vision Transformers to implicitly select task-relevant information.
TransVPR: Transformer-based place recognition with multi-level attention aggregation
use self-attention operation in vision Transformers to implicitly select task-relevant information.
- related work : Patch-Level Descriptors (e.g. Patch-NetVLAD).
![]() CosPlace: Rethinking Visual Geo-localization for Large-Scale Applications. Train as classification: Use key (from pose) to train retrieval global descriptor (as used in human face recognition), to avoid the expensive mining needed by the commonly used contrastive learning (NetVLAD).
CosPlace: Rethinking Visual Geo-localization for Large-Scale Applications. Train as classification: Use key (from pose) to train retrieval global descriptor (as used in human face recognition), to avoid the expensive mining needed by the commonly used contrastive learning (NetVLAD).
- encode pose into class id. (designed for ‘Visual geo-localization’, while not for ‘Image Retrieval’)
- divide the whole dataset into difference dataset batch (by grid), to ensure different classes are far in distance.
- Large Margin Cosine Loss (LCML), used in CosFace.
![]() NICE-SLAM: Neural Implicit Scalable Encoding for SLAM, github. a hierarchical, grid-based neural implicit encoding, multi-resolution scalable solution akin to iMAP, intuition similar to NERF.
NICE-SLAM: Neural Implicit Scalable Encoding for SLAM, github. a hierarchical, grid-based neural implicit encoding, multi-resolution scalable solution akin to iMAP, intuition similar to NERF.
![]() DM-VIO: Delayed Marginalization Visual-Inertial Odometry a better DSO-IMU, github.
DM-VIO: Delayed Marginalization Visual-Inertial Odometry a better DSO-IMU, github.
- Multi-stage IMU initializer. Dynamic photometric weight (decrease weight for overall bad image).
- Pose graph bundle adjustment.
- A second factor graph for delayed marginalization (marginalization cannot be undone, but it can be delayed).
![]() DSOL: A Fast Direct Sparse Odometry Scheme, github. Algorithmic and implementation enhancements of DSO, focus on the stereo version.
DSOL: A Fast Direct Sparse Odometry Scheme, github. Algorithmic and implementation enhancements of DSO, focus on the stereo version.
![]() Long-term Visual Map Sparsification with Heterogeneous GNN use GNN to substitute the ILP method. compare with the result using Keep it brief (paper) , my notes here (better take a look) for map summarization.
Long-term Visual Map Sparsification with Heterogeneous GNN use GNN to substitute the ILP method. compare with the result using Keep it brief (paper) , my notes here (better take a look) for map summarization.
2021
![]() gtsfm : Georgia Tech Structure from Motion, global SFM pipeline.
gtsfm : Georgia Tech Structure from Motion, global SFM pipeline.
- Union-Find approach for feature tracking.
- Estimate Cycle Consistent View Graph: remove inconsistent triplets.
- Solve by global method :
- solve camera rotation using Shonan Rotation Averaging.
- solve camera translations using Translation Averaging.
- Process a full BA. then MVS.
![]() LoFTR: Detector-Free Local Feature Matching with Transformers, github. Dense feature match driectly from two input images.
LoFTR: Detector-Free Local Feature Matching with Transformers, github. Dense feature match driectly from two input images.
![]() GVINS: Tightly Coupled GNSS-Visual-Inertial Fusion for Smooth and Consistent State Estimation It offers a complete model of GPS measurement. Makes fusion with GPS very solid.
GVINS: Tightly Coupled GNSS-Visual-Inertial Fusion for Smooth and Consistent State Estimation It offers a complete model of GPS measurement. Makes fusion with GPS very solid.
![]() DSP-SLAM: Object Oriented SLAM with Deep Shape Priors ORBSLAM2 + object tracking
DSP-SLAM: Object Oriented SLAM with Deep Shape Priors ORBSLAM2 + object tracking
![]() V-SLAM: Unconstrained Line-based SLAM Using Vanishing Points for Structural Mapping Plucher coordinate line only has normal residual term, cannot fix degeneracy cases (line on epipolar plane). This paper introduces a new residual based on vanishing point measurements.
V-SLAM: Unconstrained Line-based SLAM Using Vanishing Points for Structural Mapping Plucher coordinate line only has normal residual term, cannot fix degeneracy cases (line on epipolar plane). This paper introduces a new residual based on vanishing point measurements.
![]() Pixel-Perfect Structure-from-Motion with Featuremetric Refinement. github (1) adjust the initial keypoint locations (use CNN dense features with direct alignment); (2) refine points and camera poses.
Pixel-Perfect Structure-from-Motion with Featuremetric Refinement. github (1) adjust the initial keypoint locations (use CNN dense features with direct alignment); (2) refine points and camera poses.
2020
![]() Shonan Rotation Averaging: Global Optimality by Surfing SO(p)n. gives global optimal (which ordinary LM cannot give).
Shonan Rotation Averaging: Global Optimality by Surfing SO(p)n. gives global optimal (which ordinary LM cannot give).
- SE-Sync uses truncated-Newton Riemannian optimization on Stiefel manifold, which cannot be done in common libraries (ceres, g2o, gstam). This paper uses variables in rotation manifold, then project to Stiefel manifold. $Q=[S, V]$, $Q\in SO(p), S\in St(d, p)$. then we have $S=\pi(Q) = QP$, $P=[I_{d}; 0]$.
- Then the problem could be re-written to :
- used in
 gtsfm (along with translation averaging), a different mapping pipeline from colmap-sfm. gstam implementation
gtsfm (along with translation averaging), a different mapping pipeline from colmap-sfm. gstam implementation
![]() hloc Hierarchical-Localization. CVPR2020 winner.
hloc Hierarchical-Localization. CVPR2020 winner.
- SuperPoint 2017, SuperGlue with colmap 2016 for building map.
- Hierarchical Localization 2019 for localization. (Roughly speaking, using NetVLAD 2016 match submap with a global descriptor, then match with reference image).
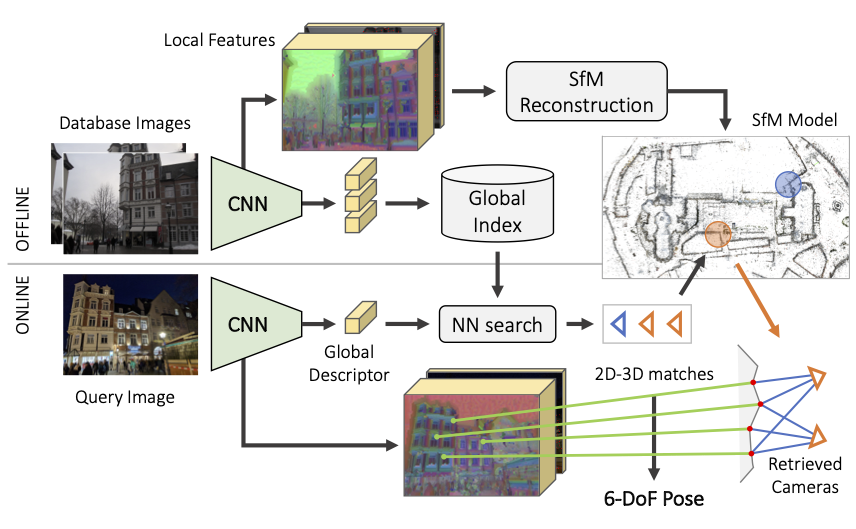
![]() Online Invariance Selection for Local Feature Descriptors Mainly for image retrieval. A light-weight meta descriptor approach to automatically select the best invariance of the local descriptors given the context. Learning the best invariance for local descriptors.
Online Invariance Selection for Local Feature Descriptors Mainly for image retrieval. A light-weight meta descriptor approach to automatically select the best invariance of the local descriptors given the context. Learning the best invariance for local descriptors.
![]() Online Visual Place Recognition via Saliency Re-identification. github project .
Online Visual Place Recognition via Saliency Re-identification. github project .
- Perform both saliency detection and retrieval in frequency domain (2D Fourier transformation).
- Saliency map : IFFT of the difference w.r.t. average filtered log spectral. Kernel cross-correlator (KCC) to match.
- No offline trainning needed. Low cost, higher recall rate than DBoW2 (as shown in the paper).
![]() Learning Feature Descriptors using Camera Pose Supervision, use camera pose (re-projected distance to epipolar line) error as loss function to train NN.
Learning Feature Descriptors using Camera Pose Supervision, use camera pose (re-projected distance to epipolar line) error as loss function to train NN.
![]() Kapture: Robust Image Retrieval-based Visual Localization using Kapture data-driven features. Instead of manually describing how keypoints or image descriptions should look like, a large amount of data is used to train an algorithm to make this decision by itself.
Kapture: Robust Image Retrieval-based Visual Localization using Kapture data-driven features. Instead of manually describing how keypoints or image descriptions should look like, a large amount of data is used to train an algorithm to make this decision by itself.
![]() Multi-View Optimization of Local Feature Geometry Refining the geometry of local image features from multiple views without known scene or camera geometry. Optimize feature keypoints’ position based on multiple views.
Multi-View Optimization of Local Feature Geometry Refining the geometry of local image features from multiple views without known scene or camera geometry. Optimize feature keypoints’ position based on multiple views.
- Process feature extraction and feature matching steps.
- Calculate visual flow $T_{u\to v}(x_{u})$ between feature matches (as the jacobians), using CNN method.
- Perform optimization for each feature track. Residual is weighted $(x_{v} - x_{u} - T_{u\to v}(x_{u}))$
![]() Cross-Descriptor Visual Localization and Mapping. “translates” descriptors from one representation to another, using NN method.
Cross-Descriptor Visual Localization and Mapping. “translates” descriptors from one representation to another, using NN method.
![]() Attention Guided Camera Localization. Roughly speaking, MapNet 2018 with attention.
Attention Guided Camera Localization. Roughly speaking, MapNet 2018 with attention.
![]() Pose Estimation for Ground Robots: On Manifold Representation, Integration, Re-Parameterization, and Optimization. Using wheel odometer and a monocular camera. Use mathematical representation of ground as the pose manifold.
Pose Estimation for Ground Robots: On Manifold Representation, Integration, Re-Parameterization, and Optimization. Using wheel odometer and a monocular camera. Use mathematical representation of ground as the pose manifold.
2019
![]() MAGSAC++, a fast, reliable and accurate robust estimator, github.
MAGSAC++, a fast, reliable and accurate robust estimator, github.
![]() OANet Learning Two-View Correspondences and Geometry Using Order-Aware Network. In short, GNN based feature matches outlier rejection.
OANet Learning Two-View Correspondences and Geometry Using Order-Aware Network. In short, GNN based feature matches outlier rejection.
![]() DIFL-FCL Domain-Invariant Feature Learning with Feature Consistency Loss. Train DL features which are robust to environment change (using GAN to generate train set). It may help when we are lack of real training images, while mostly it won’t happen.
DIFL-FCL Domain-Invariant Feature Learning with Feature Consistency Loss. Train DL features which are robust to environment change (using GAN to generate train set). It may help when we are lack of real training images, while mostly it won’t happen.
![]() Multi-Process Fusion. Ensemble methods for image retrieval process.
Multi-Process Fusion. Ensemble methods for image retrieval process.
![]() Large-scale, real-time visual-inertial localization revisited review of different methods, finally use Keep it brief (paper) , my notes here (better take a look) for map summarization.
Large-scale, real-time visual-inertial localization revisited review of different methods, finally use Keep it brief (paper) , my notes here (better take a look) for map summarization.
2018
![]() ToDayGAN. Use GAN to transform night image to bright day, then use the transformed image for image retrieval task.
ToDayGAN. Use GAN to transform night image to bright day, then use the transformed image for image retrieval task.
![]() Efficient adaptive non-maximal suppression algorithms for homogeneous spatial keypoint distribution
Efficient adaptive non-maximal suppression algorithms for homogeneous spatial keypoint distribution
- ANMS(Adaptive non-maximal suppression) based on Tree Data Structure (TDS).
- Suppression via Square Covering (SSC)
Before
![]() Distributed Very Large Scale Bundle Adjustment by Global Camera Consensus
Distributed Very Large Scale Bundle Adjustment by Global Camera Consensus
- ADMM consensus both on camera poses and map points.
- self-adaption penality & over-relaxation to improve convergence rate.
- graph cut camera-point visility graph to distribute problem.
![]() SE-Sync: A Certifiably Correct Algorithm for Synchronization over the Special Euclidean Group 2017, github code.
Produce certifiably globally optimal solutions of the special Euclidean synchronization problem, using semidefinite relaxation. This is the mathematic basis for another way to build visual map, instead of standard COLMAP–bundle adjustment SFM.
SE-Sync: A Certifiably Correct Algorithm for Synchronization over the Special Euclidean Group 2017, github code.
Produce certifiably globally optimal solutions of the special Euclidean synchronization problem, using semidefinite relaxation. This is the mathematic basis for another way to build visual map, instead of standard COLMAP–bundle adjustment SFM.
- Problem original (maximum-likelihood estimation for SE(d) synchronization) the most straight forward formule of the problem:
- Problem (Simplified maximum-likelihood estimation) simplified version of the upper problem (see the paper for $\tilde{Q}$, and if we solve rotation average problem, we will have $\tilde{Q} = L(\tilde{G}^{rho})$), then t could be derived directly from optimal R*:
- Problem relaxed (Dual semidefinite relaxation for SE(d) synchronization) (see Semidefinite Programming), solve this problem, then factorize Z* to get R* (proven by theorem in paper):
- Solve the upper relaxed problem by a further simplified unconstrained form:
- hard to solve by general interior-point methods, since Z is high dimensional.
- low-rank structure : solve a low-rank $T\in R^{r \times dn}$, s.t. $Z=Y^{T}Y$.
- in Stiefel manifold : $Y \triangleq (Y_{1}, …, Y_{n}), Y_{i} \in St(d, r)$.
- decompose $\tilde{Q}$ into sparse matrices.
- Riemannian Staircase, truncated-Newton Riemannian optimization. Global rates of convergence for nonconvex optimization on manifolds 2016.
function RiemannianStaircase(Y):
for r = r0, ..., dn + 1 do:
Starting at Y, apply a Riemannian optimization to identify
a second-order critical point Y* in St(d, r)^n of the problem.
if rank(Y*) < r then:
return Y*
else
Set Y = (Y*, 0^(1*dn))
end if
end for
end function
![]() Efficient Non-Consecutive Feature Tracking for Robust Structure-From-Motion 2016, github. during with tracking fail in video sfm: consecutive point tracking (multi-homographies match) and non-consecutive track matching.
Efficient Non-Consecutive Feature Tracking for Robust Structure-From-Motion 2016, github. during with tracking fail in video sfm: consecutive point tracking (multi-homographies match) and non-consecutive track matching.
- in video sfm, we better take advantage of feature tracking instead of pure descriptor based matching. so we could have more long track
- segment-based ba, to handle large problem.
![]() NetVLAD: CNN architecture for weakly supervised place recognition.
Triplet loss made from pose, transform the problem from ‘Image Retrieval’ to ‘Visual geo-localization’.
NetVLAD: CNN architecture for weakly supervised place recognition.
Triplet loss made from pose, transform the problem from ‘Image Retrieval’ to ‘Visual geo-localization’.
![]()
![]() Keep it brief: Scalable creation of compressed localization maps 2015 use ILP (integral linear programming) to solve the summerization problem. (worth try)
Keep it brief: Scalable creation of compressed localization maps 2015 use ILP (integral linear programming) to solve the summerization problem. (worth try)
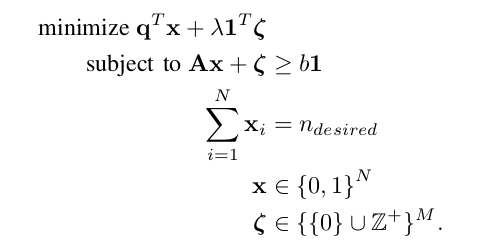
My test the upper method, see an simple example usage in github with ortools
- use google ortools to solve the ILP problem.
- use SNAP to analysis the vision map graph.
- tried this method in our benchmarks (keep 10% the map points, mean image observations drop from 1300 to 200), the localization result dropped within 10% (90% to 80%).
![]() Robust Global Translations with 1DSfM 2014, depends on the relative directions between camera poses.
Robust Global Translations with 1DSfM 2014, depends on the relative directions between camera poses.
- Problem Origin (end point j could be a camera or a point, using squared chordal distance):
- Outlier removal. project the problem into 1d space (e.g. into x axis line space) -> combinatorial ordering problem - MINIMUM FEEDBACK ARC SET problem. Solve by a greedy method.
- Solve the problem using ceres, generally converged well.
- Robust loss : Huber fits better than Cauchy.
- Using iterative Schur with jacobi preconditioning (PCG).
- Reweight camera-point edge weight by ratio, to make them less influential.
- GTSAM implementation, usage in GTSFM