Table of Contents
- Generation & GANs
- Autonomous Driving
- Image-based Rendering
- Self-Supervised Learning
- SLAM & Robotics
- Language
- AR/VR/MR
- 3D Objects
- Others
1. Generation & GANs
![]() New Generative Models for Images, Landscape Videos and 3D Human Avatars(Victor Lempitsky) 2021/02.
New Generative Models for Images, Landscape Videos and 3D Human Avatars(Victor Lempitsky) 2021/02.
- StyleGAN for Landscape Videos: DeepLandscape.
- network feature : duplicted latents - two upsampling structures (one small one large).
- discriminator : unary (use the smaller one) & pairwise (use both). warp noise maps by homography transformations.
- StyleGAN for 3D Human Avatars. SMPL-X
![]() Controllable Content Generation without Direct Supervision (Niloy Mitra) 2020/12, Smart Geometry Processing Group. Adobe.
Controllable Content Generation without Direct Supervision (Niloy Mitra) 2020/12, Smart Geometry Processing Group. Adobe.
- Industrial Design : Ideation Sketching -> CAD Modeling -> 3D model.
- DL Problems : Representation, topology + geometry + material, avoid using 3d training data.
- Learning from Rasterized Vector Data.
- Discovering Pattern Structure Using Differentiable Compositing 2020 - Pattern Expansion - Edit in the Wild, while preserving texture structure.
- Learning from Procedural 3D Data.
- Revisiting ‘Plato’s Cave’ : Escaping Plato’s Cave: 3D Shape From Adversarial Rendering 2018.
- train without access to 3d data.
- 2d image -> 3d volume -> 2d rendered image -> 2d structured samples.
- Learning Object-aware Scene Representations from Unlabeled Images/Videos.
2. Autonomous Driving
![]() A Future With Self-Driving Vehicles (Raquel Urtasun) 2021/02.
A Future With Self-Driving Vehicles (Raquel Urtasun) 2021/02.
Autonomy:
- we want a system : Trainable end-to-end & Interpretable for Validation.
- End-to-end Approaches. Direct, but not interpretable.
- Autonomy Stack.
- HD Maps /Sensors -> Perception -> Prediction -> Planning -> Control.
- Interpretable, very bad productivity.
- Joint Perception + Prediction :
- Fast and Furious 2020 lidar object prediction.
- Interaction Reasoning Network. Spatially-Aware Graph Neural Networks 2019:
- Predict considering interaction using GNN.
- Predicting Marginal Distributions: real world decision should be discrete - consider scenarios separately.
- V2VNet 2020: share NN-encoded sensor data between vehicles -> then using GNN. Simulation.
- Joint Perception + Prediction + Planning : Uber ATG Vision: Interpretable Neural Motion Planer
- Neural Motion Planer 2019, add a branch from the network as planner -> time & egocar position.
- DSDNet 2020. (1) multi-modal socially-consistent uncertainty; (2) explicitly condition on prediction; (3) use prior (human) knowledge.
- P3: Safe Motion Planning Through Interpretable Semantic Representations. Recurrent semantic occupancy map -> to avoid occupied regions.
Simulation: Structured Testing, Real World Replay, Sensor Simulation.
- Lidar simulation : TrafficSim 2021, use real world data (real 3D Assets) to generate preception & prediction data.
- Camera (multi-camera video) simulation : GeoSim 2021, use real world data to generate (through multi-view mulit-sensor reconstruction network).
3. Image-based Rendering
![]() Neural Implicit Representations for 3D Vision (Andreas Geiger) 2020/09. cvpr talk pdf.
Neural Implicit Representations for 3D Vision (Andreas Geiger) 2020/09. cvpr talk pdf.
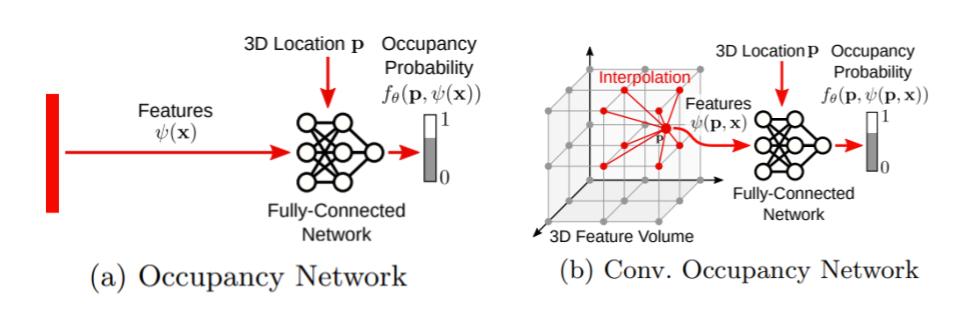
- 3d representations:
- Direct representation : voxels, points, meshes.
- Implicit representation : decision boundary of a non-linear classifier.
- Occupancy Network : $L(\theta, \phi) = \sum_{j=1}^{K}BCE(f_{\theta}(p_{ij}, z_{i}), o_{ij}) + KL[q_{\phi}(z|(p_{ij}, o_{ij}))|p_{0}(Z)]$.
- Given the 3d model, we can further do : Texture Fields 2019 predicts each 3d point a color. Occupancy Flow 2019 predicts 4d - occupancy and velocity.
- Differentiable Volumetric Rendering 2020: 3d points + encoded image vector -> occupancy and color (for all points).
- forward pass (rendering) : find surface point along the pixel ray, and get color.
- backward pass : gradient based on color difference from pixel re-projection.
- NERF: integrate all the points in the ray to get color and depth. (while Occupancy Network used only the occupied one)
- GRAF 2020 predict without camera poses. sample rays (patch) and use discriminator.
- Convolutional Occupancy Networks 2020, uses 3d feature volume.
- can also use Fourier Features 2020, fourier feature fits better MLP.
![]() Reconstructing the Plenoptic Function (Noah Snavely) 2020/10, Notes.
Reconstructing the Plenoptic Function (Noah Snavely) 2020/10, Notes.
![]() Understanding and Extending Neural Radiance Fields (Jonathan T. Barron) 2022/10, Jonathan T. Barron. See more in My Neural Rendering Page, My Deep Learning 3D Reconstruction Page.
Understanding and Extending Neural Radiance Fields (Jonathan T. Barron) 2022/10, Jonathan T. Barron. See more in My Neural Rendering Page, My Deep Learning 3D Reconstruction Page.
- NeRF.
- How NeRF Work ? Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. Experiments.
- Toy problem : memorizing a 2d image, a network to predict color for pixel.
- coordinate to color - (x, y) to (r, g, b). failed.
- coordinate’s Fourier feature (~
positional encoding ) to color. succeed.
- Neural Tangent Kernel (neural networks are kernel regression + ReLU MLPs corresponding to a ‘dot product’ kernel).
- with Dot Product of Fourier Features. MLPs are made into "convolution".
- See Instant Neural Graphics Primitives for a great implementation.
- Toy problem : memorizing a 2d image, a network to predict color for pixel.
- Nerf in the Wild with appearance & transient embedding.
![]() Learning to Retime People in Videos (Tali Dekel) 2020/10
Learning to Retime People in Videos (Tali Dekel) 2020/10
- Analyzing, Visualizing and Re-rendering people in videos.
- motion visualization, depth prediction, SpeedNet : adaptive speed up video
- Change the speed of individual people within frames. Layered Neural Rendering for Retiming People in Video.
interesting work! - Key challenges : space-time correlations; occlusions/dis-occlusions.
- Layered Decomposition, then we can edit the video by changing the layers.
![]() Reflections on Image-Based Rendering (Richard Szeliski) 2021/01. A overview.
Reflections on Image-Based Rendering (Richard Szeliski) 2021/01. A overview.
- Multi-View Stereo. Usage : View Interpolation, View Morphing, interactive 3d scene, etc. Idea behind: Plane Sweep Stereo (~Patch Match).
- Image-Based Rendering: Depth Layers, Multi-plane Images.
- 360 video (panorama).
- 360 with complete light field: Google Jump 2015, Facebook Surround 360 2016. Stereo with two 360 cameras.
- Immersive Video Stabilization by ‘Spatio-Temporal MRF Stitch’ : reconstruction and merge pictures.
- Large Scale Reconstruction based: cross fade between images to move from one image to other: Photo Tourism: Exploring Photo Collections in 3D, using images. Piecewise Planar Stereo for Image-based Rendering 2009, using depth layers. Ambient Point Clouds for View Interpolation 2010, using point cloud.
- Simgle-Image based:
- Practical 3D Photography 2018, using iphone depth sensor.
- Using mono-depth: One Shot 3D Photography 2020. And ‘google photos cinematic effect’.
- Reflections and transparency : Rear layer & normal layer. Gradient domain depth.
- Neural Rendering.
- SynSin: End-to-end View Synthesis from a Single Image 2019. predict a heuristic depth map. multi-plane images with depth feature, with a decoder to generate new view.
- Animating Pictures with Eulerian Motion Fields 2021. predict a heuristic motion map. tracing the motion of depth features, and with a decoder to generate new view.
![]() Neural Fields Beyond Novel View Synthesis (Andrea Tagliasacchi) 2023/01: View understanding, Camera knowledge, Overfitting regime. NeRF : geometry + appearance.
Neural Fields Beyond Novel View Synthesis (Andrea Tagliasacchi) 2023/01: View understanding, Camera knowledge, Overfitting regime. NeRF : geometry + appearance.
- Learn from One Look 2022, conditioned NeRF model. hard surface loss to remove smoke effect.
- Fast NeRF Rendering, Nerual Textured Mesh. MobileNeRF 2022.
- previous works : fast train (instant-ngp), fast rendering (different representation : NVDiffRec, Nerual-PIL, hardware limitation : FastNerf, DONeRF, KilNerf, SNeRG).
- Scene is a (nerual) textured mesh. And small MLP to rasterize.
- Neural Semantic Field 2022: field-to-field translation network.
- Neighbor analysis the field, then generate new field.
- nerf2nerf: Pairwise Registration of Neural Radiance Fields 2023, pairwise alignment of neural fields.
4. Self-Supervised Learning
![]() On Removing Supervision from Contrastive Self-Supervised Learning 2021/01 by Alexei Efros. Self-Supervised Learning (use the tools of supervised learning, but with raw data instead of human-provided labels):
On Removing Supervision from Contrastive Self-Supervised Learning 2021/01 by Alexei Efros. Self-Supervised Learning (use the tools of supervised learning, but with raw data instead of human-provided labels):
- Self-Supervised Learning Allow to get away from top-down (semantic) categorization. (jump out of concrete objects, to reach IDEE of Plato)
- Per-exemplar SVM : Recognition by Association via Learning Per-exemplar Distances 2008, Exemplar-SVM 2011, Exemplar-CNN 2014.
- Similarity Learning (Constrastive Learning), learning the distances between data.
- Data Augmentation boost similarity learning. and even as supervision to learning (“leak in”) - What Should Not Be Contrastive in Contrastive Learning 2021.
- Constrastive Learning without Data Augmentation -
Time as Supervisory Signal (Temporal Continutiy is important to animals):- Video as graph.
- Contrastive Learning for Unpaired Image-to-Image Translation 2020: using GAN loss, close in structure space, and far in texture space.
- Self-Supervised Learning Enable continuous life-long learning.
- we never see the same ‘training data’ in real life. Data augmentation encourage memorizing. -> Online Continual Learning. keep using new data to train.
- Test-Time Training 2020, use self-supervised to adapt new data.
- (
实践是交互性的,机器要想更像人就也需要实践,那么仅仅单向地给它数据肯定是不够的,需要它以一种方式和客体发生作用才行。而且这种作用不能只是机械的,而且需要有“能动性”。 )
![]() Learning Representations and Geometry from Unlabeled Videos (Andrea Vedaldi) 2021/01. horizontal problems, vertical problems.
Contrastive Learning : vector representations.
Learning Representations and Geometry from Unlabeled Videos (Andrea Vedaldi) 2021/01. horizontal problems, vertical problems.
Contrastive Learning : vector representations.
- Video Timeshift and Inverse: Multi-modal Self-Supervision from Generalized Data Transformations
- Video with Caption: Captioning as a modality for contrastive learning. Support-set bottlenecks for video-text representation learning, using cross-captioning to be robust against wrong caption.
- Image/Video Labelling:
- Clustering the representation vectors. Deep Clustering for Unsupervised Learning of Visual Features learns the clustering and the representation network.
- Self-labelling via simultaneous clustering and representation learning, label assignment by probability.
- Labelling unlabelled videos from scratch with multi-modal self-supervision
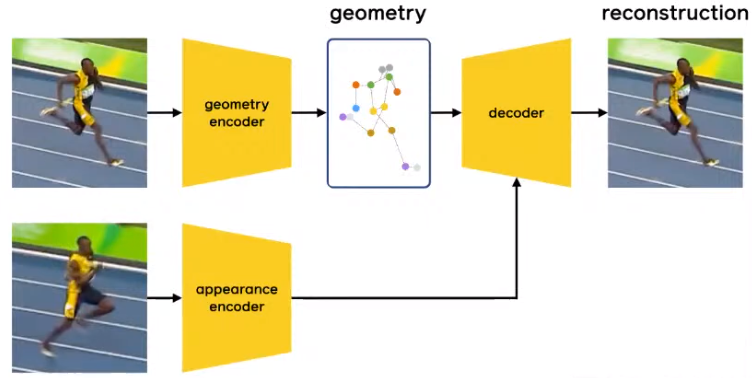
- Video-to-Geometry:
Autoencoding encode to 'shape code' (2d landmarks), then use decoder to reconstruct the original image .- Learning Landmarks from Unaligned Data using Image Translation.
- Exemplar Fine-Tuning for 3D Human Model Fitting, video to human 3d model.
- C3DPO - Canonical 3D Pose Networks for Non-rigid Structure From Motion. 2d landmarks to predict model and camera pose.
- Canonical 3D Deformer Maps, predicts both depth maps and canonical maps.
- Texture transfer, Use Symmetry as supervision.
5. SLAM & Robotics
![]() New Methods for Reconstruction and Neural Rendering (Christian Theobalt) 2020/11
New Methods for Reconstruction and Neural Rendering (Christian Theobalt) 2020/11
- Monocular reconstruction : human hand, human skeleton, human performance (surface), 3d face.
- Nerf : Deep relightable texture. StyleRig -> pose & light.
- Neural Sparse Voxel Fields 2020.
![]() Pushing Factor Graphs beyond SLAM (Frank Dellaert) 2020/12, GTSAM. Factor Graph Introduction. user case : Skydio drone, navigation, tracking and motion planning.
Pushing Factor Graphs beyond SLAM (Frank Dellaert) 2020/12, GTSAM. Factor Graph Introduction. user case : Skydio drone, navigation, tracking and motion planning.
- SLAM & GTSAM. Sparse Hessian Matrix - Bayes Tree : Incremental & Distributed (sub-trees).
- iSAM 2012, (ICE-BA 2018).
- Structure from Motion. GTSFM (
it is really a nice work. ), parallelize SFM over large clusters, using DASK.- DMV (Detection/Description + Matching + Verification) -> Essential Matrix.
- Shonan Rotation Averaging
- Navigation and Control. IMU-preintegration factor is integrated inside GTSAM.
- More.
- Batch and Incremental Kinodynamic Motion Planning using Dynamic Factor Graphs. use factor graphs to encode robot dynamics and applied to kino-dynamic motion planning.
- Optimize control parameters for drone planning.
- SwiftFusion integration with TensorFlow, functions can be made differentiable automatically.
![]() Sights, Sounds, and Space: Audio-visual Learning in 3D (Kristen Grauman) 2020/12. Objective : indoor robot mapping & navigation.
Sights, Sounds, and Space: Audio-visual Learning in 3D (Kristen Grauman) 2020/12. Objective : indoor robot mapping & navigation.
- SoundSpaces : Realistic 3D environments and simulation - with 3D sound.
- Audio-visual embodied Navigation 2019 : vision + audio + gps -> Critic + Actor -> Action Sampler. (Finding alert task).
- audio-visual waypoints.
- Semantic audio-visual Navigation 2020, put all the environmental noise together.
- Audio-Visual Floorplan Reconstruction 2020, github, semantic room mapping. sound contains information of geometry.
- VisualEchoes: Spatial Image Representation Learning through Echolocation 2020. agent make sound, and listen the echos. Supervision from acoustically interacting with the physical world.
very interesting topic! - help in depth/normal estimation and navigation tasks.
- VisualEcho-Net + Echo-Net -> Predict Orientation. (self-supervised echo and visual results should match)
![]() Towards Graph-Based Spatial AI (Andrew Davison) 2020/10. SLAM evolving into Spatial AI.
Towards Graph-Based Spatial AI (Andrew Davison) 2020/10. SLAM evolving into Spatial AI.
- FutureMapping: The Computational Structure of Spatial AI Systems 2018
- Representation is important (End-to-end might not be possible).
- There should be a generality to Spatial AI system (for various applications).
- SLAM: MonoSLAM 2003, ElasticFusion 2016, SemanticFusion 2017.
- New Representations for Spatial AI:
- keyframes : CodeSLAM 2018, SceneCode 2019, per-frame code for depths & semantics.
- Dynamic Scene Graphs. SLAM with objects : MoreFusion 2020, NodeSLAM 2020.
- Hardware : Event Cameras. (Code Design on) Processors.
- Gaussian Belief Propagation for Spatial AI: propagate the covariance of each node, through the graph.
![]() A Question of Representation in 3D Computer Vision (Bharath Hariharan) 2020/09. Task: image -> 3d bbx and 3d shape output. performs badly on various benchmarks.
A Question of Representation in 3D Computer Vision (Bharath Hariharan) 2020/09. Task: image -> 3d bbx and 3d shape output. performs badly on various benchmarks.
- NN to include inductive biases for 3d reasoning. large gap between stereo (depth image based NN) & lidar (pointcloud based NN).
- 2d depth neighborhood is not 3d neighborhood, 2d convolution not ideal for 3d structure.
- Psudo Lidar Pipeline : PLUMENet: Efficient 3D Object Detection from Stereo Images 2021, convert depth image to Bird-Eye-View -> significantly narrow the gap.
- Ouput representation of 3d that capture priors, allow learn from pointcloud.
- Training regimes that remove reliance on millions of labeled examples.
- feature descriptors training:
- need 2d match ground truth generated by SFM -> Biased.
- image homography : limited.
 Learning Feature Descriptors using Camera Pose Supervision, github.
Learning Feature Descriptors using Camera Pose Supervision, github.
- camera pose -> epipolar loss.
- differentiable matching : probability distribution (heat map).
- feature descriptors training:
![]() Learning to Walk with Vision and Proprioception (Jitendra Malik) 2022/01. “we see in order to move and we move in order to see”. “Anaxogaras: It is because of his being armed with hands that man is the most intelligent animal”. Rapid Motor Adaptation for Legged Robots 2021
Learning to Walk with Vision and Proprioception (Jitendra Malik) 2022/01. “we see in order to move and we move in order to see”. “Anaxogaras: It is because of his being armed with hands that man is the most intelligent animal”. Rapid Motor Adaptation for Legged Robots 2021
- Walking in simulation.
- Pervious Works: Animal Gaits. Computational Gaits - Central Pattern Generators. Real People Gaits.
- RL: Environmental Factor Encoder + State & Old Action -> Base Policy -> Action. While minimize work and ground impact.
- Walking in real world (blindly) via rapid motor adaption.
- Some of the environment variables are unavailable. Adaptation Module : Use history action&state to estimate the environment variables.
- Adaptation Module can be pre-trained in simulation by Environmental Factor Encoder.
- Walking at different linear and angular velocities in the real world (change target speed): Minimizing Energy Consumption Leads to the Emergence of Gaits in Legged Robots 2021.
- Robots shows different gaits at different speed.
- Navigation to a point goal with vision and proprioception: Coupling Vision and Proprioception for Navigation of Legged Robots 2021, robot with RGBD camera.
- Occupancy Map & Cost Map -> Velocity Command Generator.
- Epliogue : Layered Sensorimotor Architectures meet Deep RL.
6. Language
![]() Explainability and Compositionality for Visual Recognition (Zeynep Akata) 2021/01.
Explainability and Compositionality for Visual Recognition (Zeynep Akata) 2021/01.
- Learning with Explanation with Minimal Supervision — Zero-Shot Learning.
- Image -> Image Features <-(F)-> Class Attributes <- Class Labels.
- Zero-Shot Learning Train the mapping F. But human made Attributes is needed.
- Data Augmentation : Text-to-Image GAN. Text-to-ImageFeature GAN/VAE.
- Generating Explanations using Attributes and Natural Language — Image-to-Text.
- towards effective human-machine communication.
- Summary, Ongoing work and future work.
7. AR/VR/MR
![]() Photorealistic Telepresence (Yaser Sheikh) 2020/12, from facebook. Face-to-face social interaction in distance. True presence rather than “perceptually plausible” — Enable Authentic Communication in Artificial Reality.
Photorealistic Telepresence (Yaser Sheikh) 2020/12, from facebook. Face-to-face social interaction in distance. True presence rather than “perceptually plausible” — Enable Authentic Communication in Artificial Reality.
- CODEC AVATARS : Deep Appearance Models for Face Rendering 2018
- Encoder/Decoder structure : Human -(encoder)-> code -(decoder)-> Texture & Mesh -> Face.
- Training Data : Mugsy - all angle camera shot.
- sensors : 4 eye cameras, 3 month cameras.
- Nerf based 3d reconstruction.
- Hand Tracking, even very complex gestions. Constraining Dense Hand Surface Tracking with Elasticity 2020.
- Audio.
8. 3D Objects
![]() AI for 3D Content Creation (Sanja Fidler) 2020/09,
AI for 3D Content Creation (Sanja Fidler) 2020/09, ![]() NVIDIA Kaolin.
NVIDIA Kaolin.
- Manual Creation is Slow (e.g. GTA).
- Worlds (Scene Composition) :
- Scene layout : probabilistic grammar, Meta-Sim 2019, Meta-Sim2 2020: (1) encode scene with GNN; (2) distribution matching by comparing images; (3) task optimization.
- Assets : Make graphic rendering differentiable -> able to train.
- car generation : StyleGANRender 2021.
- DefTet 2020, deform Tetrahedral Meshes.
- Other works. GameGAN 2020
![]() Shape Reps: Parametric Meshes vs Implicit Functions (Gerard Pons-Moll) 2020/09, Realistic virtual humans : generation & perception, with different representations.
Shape Reps: Parametric Meshes vs Implicit Functions (Gerard Pons-Moll) 2020/09, Realistic virtual humans : generation & perception, with different representations.
- SMPL : A Skinned Multi-Person Linear Model 2015-2022
- Parametric Meshes. Self-supervised using video : video -> pose, shape, close -> 3d model -> video.
- SMPL + Cloths : People Snapshot Dataset 2018: pose, shape, cloth.
- SMPL + Garments : MULTI-GARMENT NET 2019. predict body and garment models. TAILORNET 2019 learn cloths deform.
- Mesh based representation cannot handle complicate topology.
- Implicit Functions. (~SDF).
- Implicit Functions Net - For 3D Shape Reconstruction and Completion 2020: multi-scale grid features -(decoder)-> [0, 1] (inside/outside).
- work for watertight surfaces only. cannot model open manifold, nor inner structures.
- Neural Distance Field 2020 : predict [0, 1] -> R (unsigned distance).
- Implicit Functions Net - For 3D Shape Reconstruction and Completion 2020: multi-scale grid features -(decoder)-> [0, 1] (inside/outside).
- Hybrid Model.
- Unsupervised Shape and Pose Disentanglement for 3D Meshes 2020 pose and shape to control output, with implicit code.
![]() Joint Learning Over Visual and Geometric Data (Leonidas Guibas) 2021/08.
Joint Learning Over Visual and Geometric Data (Leonidas Guibas) 2021/08.
- Multi-Modal 3D object Detection.
- SE3 equivalent networks.
- Category-Level Object Pose Estimation.
- Latent Spatio-Temporal Representations.
- Exploiting Consistency among Learning Tasks.
![]() Making 3D Predictions with 2D Supervision (Justin Johnson) 2022/08
Making 3D Predictions with 2D Supervision (Justin Johnson) 2022/08
- Mesh R-CNN 2019 : Supervised Shape Prediction, single image -> 3d bbx detection with mesh.
- Pixel2Mesh 2018: Iterative mesh refinement (deformation), but has limitation on topology.
- this paper -> deforming 3d object voxels into mesh.
 Differentiable Rendering + PyTorch3d 2020, differentiable render 3d geometry to 2d to make 2d loss.
Differentiable Rendering + PyTorch3d 2020, differentiable render 3d geometry to 2d to make 2d loss.
- Traditional Pipeline: Rasterization (not differentiable: boundaries are not continuous) + Shading.
- Solution SoftRas 2019: blur the boundary to be continuous.
- Refinement this paper (more efficient): K nearest faces; coarse-to-fine; move shading to pytorch; heterogenous batching.
- Unsupervised Shape Prediction from single view, trained with Differentiable Rendering.
- Trained with a second view. Mesh predicts: offset for each vertex (from template sphere mesh).
- Sphere GCN (graph convolution) model (out performs Shpere FC).
- SynSin : Single-Image View Synthesis 2020, trained by images (video) only.
- Predict per-pixel features + depth.
- Projection by transformation (features & depth) to new view.
- Generator to predict image.
9. Others
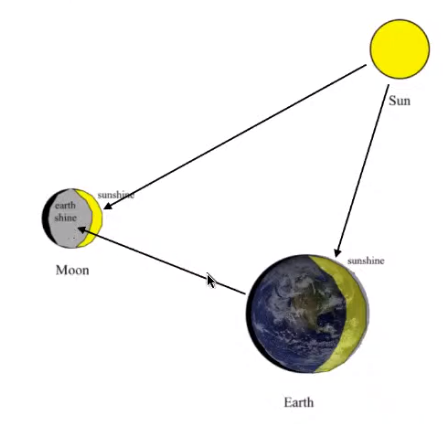
![]() The Moon Camera (Bill Freeman) 2020/10. attempts to photograph the Earth from space using the moon as a camera, and several Computational imaging projects resulting from those attempts.
The Moon Camera (Bill Freeman) 2020/10. attempts to photograph the Earth from space using the moon as a camera, and several Computational imaging projects resulting from those attempts.
- Approaches 1. Measuring diffuse reflections of Earthshine from the Moon.
- Sphere Render : Visual Appearance of Matte Surfaces 1995. Probability model : Light transport matrix + Prior Covariance + Noise.
- Non-line-of-sight image research.
- Approaches 2. Observing the fuzzy boundaries of cast shadows of Earthshine on the Moon.
- Crater - shadows border changes, as different amount of Earthshine is available.
- Occlusion-based imaging : Corner camera: Turning Corners Into Cameras: Principles and Methods 2017. shadow edge contains information behind the wall.
- Approaches 3. Measuring the specular reflections of modulations within sunlight.
- Intensity change; spectrum change; modulation spectrum change.