Table of Contents
1. HD-Map
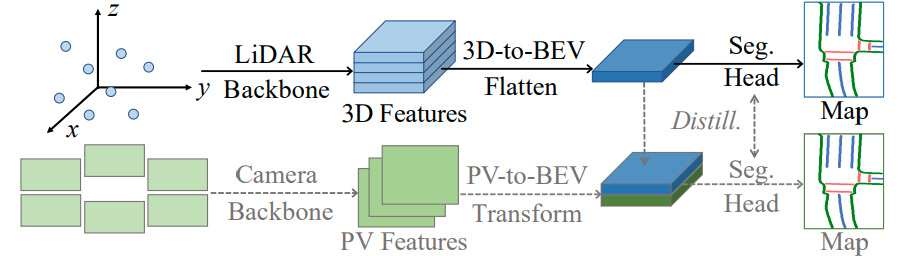
![]() LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation 2023 generate HD map with lidar and BEV images.
LiDAR2Map: In Defense of LiDAR-Based Semantic Map Construction Using Online Camera Distillation 2023 generate HD map with lidar and BEV images.
![]() High-Definition Map Generation Technologies For Autonomous Driving 2022
High-Definition Map Generation Technologies For Autonomous Driving 2022
- Data collection methods.
- Point cloud map generation methods. Better see Lidar mapping algorithm papers.
- Feature extraction methods for HD maps.
- Road Network Extraction:
- 2D Aerial Images : segmentation-based, iterative graph growing, and graph-generation methods.
- 3D Point Clouds (using segmentation).
- Sensor Fusion Methods : use both pcls, (aerial/car) images, GPS trajectories.
- Road Markings Extraction : 2D (aerial/car) images or 3D point clouds (bottom-up method and top-down method).
- Pole-like Objects Extraction: usually based on segmentation and classification on MLS 3D point clouds
- Road Network Extraction:
- Framework for HD maps:
- Lanelet2 : physical layer (points and lines), relational layer, and topological layer.
- OpenDRIVE : reference line/road (various geometric primitives), lane, and features.
- Apollo Maps : uses points. Road, Intersection, Traffic signal, Logical relationship & Others.
![]() Localization using HD map:
Localization using HD map:
- YOLOP: You Only Look Once for Panoptic Driving Perception 2021, YOLO for car images.
- Coarse-to-fine Semantic Localization with HD Map for Autonomous Driving in Structural Scenes 2021, segmentation to gradient map, use direct method for pose refinement.
![]() Computing Systems for Autonomous Driving: State-of-the-Art and Challenges 2020. focus on hardware side.
Computing Systems for Autonomous Driving: State-of-the-Art and Challenges 2020. focus on hardware side.
![]() Towards End-to-End Lane Detection: an Instance Segmentation Approach 2018, github lane segmentation.
Towards End-to-End Lane Detection: an Instance Segmentation Approach 2018, github lane segmentation.
![]() Computer Recognition of Roads from Satellite Pictures 1976
Computer Recognition of Roads from Satellite Pictures 1976
2. Learning to Drive
Take advantages of Transformers.
- Traditional CV missions (classification, segmentation, etc) are not fit for auto-drive mission.
- Compared to ChatGPT, these models are small. No large model in general Computer Vision yet.
- Or we might not be able to dig vision data from internet as NLP did - no easy ‘gt’ could be found.
- The driving task is still too simple, does not require high level understanding. (we need a better task to dig visual based AI, text-image related tasks might be good)
Make Large Dataset from online videos: how to make large dataset:
- video online: no calibration, vision only, on real scale.
- slam mapped dataset (require online video mapping algorithm).
![]() Planning-oriented Autonomous Driving 2023. Large model for auto-drive, an end-to-end paradigm unites modules in perception and prediction. Combine different models together, and jointly optimize them. Made a good starting point for further work.
Planning-oriented Autonomous Driving 2023. Large model for auto-drive, an end-to-end paradigm unites modules in perception and prediction. Combine different models together, and jointly optimize them. Made a good starting point for further work.
![]() PPGeo: Policy Pre-training for Autonomous Driving via Self-supervised Geometric Modeling 2023.
PPGeo: Policy Pre-training for Autonomous Driving via Self-supervised Geometric Modeling 2023.
- In the first stage, the geometric modeling framework generates pose and depth predictions simultaneously, with two consecutive frames as input.
- In the second stage, the visual encoder learns driving policy representation by predicting the future ego-motion and optimizing with the photometric error based on current visual observation only.
- Decision Intelligence Platform for Autonomous Driving simulation.
![]() ACO: Learning to Drive by Watching YouTube videos: Action-Conditioned Contrastive Policy Pretraining 2022. Use ‘pseudo label of action’ (made by a supervised - Inverse dynamics model) to make a model ‘learn the features that matter to the output action’, which could be further transformed to other tasks.
ACO: Learning to Drive by Watching YouTube videos: Action-Conditioned Contrastive Policy Pretraining 2022. Use ‘pseudo label of action’ (made by a supervised - Inverse dynamics model) to make a model ‘learn the features that matter to the output action’, which could be further transformed to other tasks.
- data set list, data set drive.
- Train with : Instance Contrastive Pair (ICP) and Action Contrastive Pair (ACP).
- Inverse dynamics : DL Dense Optical Flow RAFT.
![]() TCP - Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline 2022. two branches for trajectory planning and direct control, respectively.
TCP - Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline 2022. two branches for trajectory planning and direct control, respectively.
![]() Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos 2022, openai page. Learn to act by watching Minecraft game videos. Fun!. gets pseudo action labels from a trained Inverse Dynamics Model.
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos 2022, openai page. Learn to act by watching Minecraft game videos. Fun!. gets pseudo action labels from a trained Inverse Dynamics Model.
![]() Momentum Contrast for Unsupervised Visual Representation Learning 2020, github page. Contrastive learning creates supervisory labels via considering each image (instance) in the dataset forms a unique category and applies the learning objective of instance discrimination.
Momentum Contrast for Unsupervised Visual Representation Learning 2020, github page. Contrastive learning creates supervisory labels via considering each image (instance) in the dataset forms a unique category and applies the learning objective of instance discrimination.