Table of Contents
1. End-to-end Regression
input image, directly return the pose (3dof/6dof).
Pose Regression:
 PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization 2015. Learn the scene, then produce pose for an input image.
PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization 2015. Learn the scene, then produce pose for an input image.
Geo-Localization as Classification (GPS coordinate as label):
 Where We Are and What We’re Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes 2023, world-wide visual geo-localization.
Where We Are and What We’re Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes 2023, world-wide visual geo-localization.
- use S2 block division (size depends on image available in block).
- localize considering
16 scene and 7 hierarchies .
2. DL depth + DL flow -> Pose
![]() DiffPoseNet: Direct Differentiable Camera Pose Estimation 2022, project page.
(1) Get relative pose based on dense optical flow, and image depth.
(2) NFlowNet and Coarse PoseNet together to get fine pose.
DiffPoseNet: Direct Differentiable Camera Pose Estimation 2022, project page.
(1) Get relative pose based on dense optical flow, and image depth.
(2) NFlowNet and Coarse PoseNet together to get fine pose.
![]() Towards Better Generalization: Joint Depth-Pose Learning without PoseNet 2020. DeepFlow -> compute fundamental matrix. -> sparse pcl -> Rescale DeepDepth result.
Towards Better Generalization: Joint Depth-Pose Learning without PoseNet 2020. DeepFlow -> compute fundamental matrix. -> sparse pcl -> Rescale DeepDepth result.
3. Match + (Relative) Pose
3.1 Dense Image 2d Matching
- Map: images with poses.
- Query Pipeline: Retrieval + Match Features + Relative Poses + Pose Averaging -> Query Camera Pose.
![]() DKM: Dense Kernelized Feature Matching for Geometry Estimation 2023. directly output points matches with two input images.
DKM: Dense Kernelized Feature Matching for Geometry Estimation 2023. directly output points matches with two input images.
![]() LoFTR: Detector-Free Local Feature Matching with Transformers 2021. directly output points matches with two input images.
LoFTR: Detector-Free Local Feature Matching with Transformers 2021. directly output points matches with two input images.
3.2 Image-Scene 2d-3d Matching
Scene Coordinate Regression:
![]() Accelerated Coordinate Encoding 2023. From Niantic, small scene localization using DL method - fast and high accuracy. Fits well to Niantic’s LightShip (small region vlp around landmarks).
Accelerated Coordinate Encoding 2023. From Niantic, small scene localization using DL method - fast and high accuracy. Fits well to Niantic’s LightShip (small region vlp around landmarks).
- predict a 3d scene coordinate for each input image patch, then apply PNP ransac for pose estimation.
- accelerate the trainning loop, compare to DSAC*.
- For few-shot mapping:
use the encoder to get descriptors for each image patch, following by NN match + Triangulation to get 3d position. Use NN to find corresponding 3d points by descriptors. . ace encoder test
![]() Learning to Detect Scene Landmarks for Camera Localization 2022, github. predict 2d localization of a predefined scene landmark (predict heat map for each scene landmark).
Learning to Detect Scene Landmarks for Camera Localization 2022, github. predict 2d localization of a predefined scene landmark (predict heat map for each scene landmark).
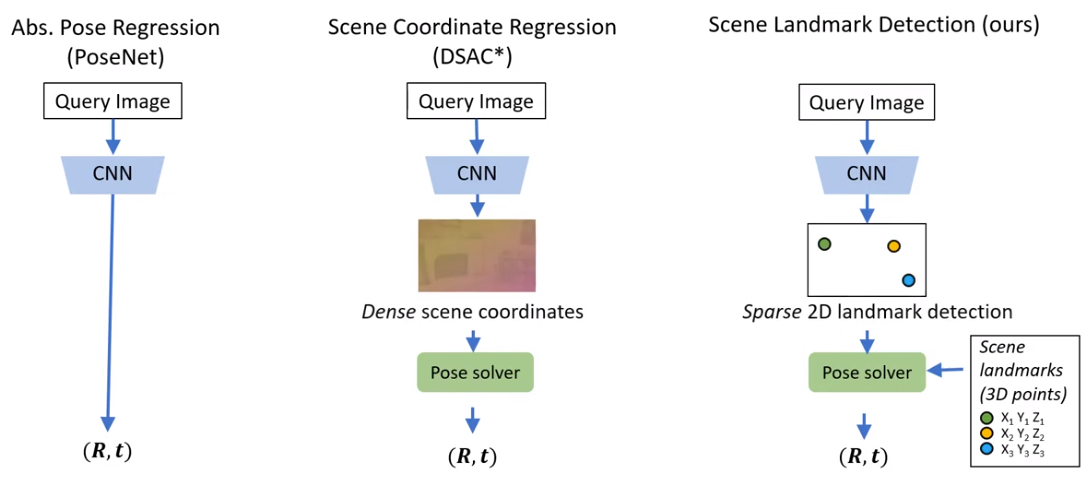
![]() Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC 2021. predict scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment.
Visual Camera Re-Localization from RGB and RGB-D Images Using DSAC 2021. predict scene coordinates, i.e. dense correspondences between the input image and 3D scene space of the environment.
4. Overhead Image localization
global image descriptor-based (limited by sampling density of satellite images, mostly need panorama image as input):
- Spatialaware feature aggregation for image based cross-view geolocalization 2019 panorama - aerial image, localization (with north direction known). global descriptor retrieval.
- use
regular polar transform to warp an aerial image such that its domain is closer to that of a ground-view panorama. SAFA : Spatial-aware Feature Aggregation with an attention mechanism.- require reference image at the same (close) location inside database.
- use
- VIGOR: Crossview image geo-localization beyond one-to-one retrieval 2021, github. panorama - aerial image, localization.
- has
coarse-to-fine :- global descriptor image retrieval.
- within-image calibration (using a MLP to predict offset from descriptors).
- it
beyond one-to-one : re-weight the embeddings in accordance with their positions.
- has
- Visual cross-view metric localization with dense uncertainty estimates 2022. use raw aerial image to refine pose, after global retrieval.
- Accurate 3-dof camera geo-localization via ground-to-satellite image matching 2022, use both polar transform and the projective transform.
- SliceMatch: Geometry-guided Aggregation for Cross-View Pose Estimation 2023. compute
column-wise-slice image descriptors , to enable return orientation.
dense pixel-level feature-based (using the geometric relationship - as camera pose optimization):
- Beyond Cross-view Image Retrieval: Highly Accurate Vehicle Localization Using Satellite Image 2022, github. Given a coarse initial estimation, optimize pose based on
the projection error of the satellite deep features to a ground viewpoint.- 3d point reprojection error, using coarse-to-fine LM.
- setting all the points in ground image on ground (to have 3d points).
- pose error as the trainning loss.
- Satellite Image Based Cross-view Localization for Autonomous Vehicle 2023, the same pipeline as upper paper, but with more refinement.
 OrienterNet: Visual Localization in 2D Public Maps with Neural Matching 2023,
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching 2023, ETH, META , github.- Bird’s-Eye View inference (given height & gravity), encode input image to BEV.
- Map encoding, encode the raster map (from OSM).
- BEV-map matching, to get 3dof (x,y,yaw) pose.